Vysvětlení p-hodnot pro začínající datové vědce / Habr
Pamatuji si, že když jsem dělal svou první zahraniční stáž v CERNu jako výzkumný asistent, většina lidí stále mluvila o objevu Higgsova bosonu poté, co bylo potvrzeno, že splňuje práh pěti sigma (což znamená, že měl p-hodnotu 0,0000003).

Tehdy jsem nevěděl nic o p-hodnotách, testování hypotéz nebo dokonce statistické významnosti.
Rozhodl jsem se vygooglovat slovo „p-value“ a to, co jsem našel na Wikipedii, mě ještě více zmátlo.
Při testování statistických hypotéz p-hodnota nebo hodnota pravděpodobnosti pro daný statistický model je to pravděpodobnost, že při dané nulové hypotéze bude statistický souhrn (např. absolutní hodnota středního rozdílu vzorku mezi dvěma porovnávanými skupinami) větší nebo roven skutečným pozorovaným výsledkům.
– Wikipedia
Dobrá práce, Wikipedie.
OK. Nechápal jsem, co to p-hodnota vlastně znamená.
Jak jsem se ponořil hlouběji do oblasti datové vědy, konečně jsem začal chápat význam p-hodnoty a to, kde ji lze použít jako součást rozhodovacích nástrojů v určitých experimentech.
Proto jsem se rozhodl vysvětlit p-hodnotu v tomto článku a jak ji lze použít při testování hypotéz, abych vám dal lepší a intuitivní pochopení p-hodnot.
Také nemůžeme přeskočit základní pochopení jiných pojmů a definici p-hodnoty, slibuji, že toto vysvětlení udělám intuitivním, aniž bych vás zahltil všemi technickými termíny, na které jsem narazil.
V tomto článku jsou čtyři části, které vám poskytnou úplný obrázek od sestavení testu hypotézy po pochopení hodnoty p a její použití ve vašem rozhodovacím procesu. Vřele doporučuji projít si všechny, abyste získali podrobné pochopení p-hodnot:
- Testování hypotéz
- Normální rozdělení
- Co je to P-hodnota?
- Statistická významnost
1. Testování hypotéz
Než si řekneme, co znamená p-hodnota, začněme tím, že se podíváme na testování hypotéz, kde se p-hodnota používá k určení statistické významnosti našich výsledků.
Naším konečným cílem je určit statistickou významnost našich výsledků.
A statistická významnost je postavena na těchto 3 jednoduchých myšlenkách:
- Testování hypotéz
- Normální rozdělení
- P-hodnota
Jinými slovy, vytvoříme nárok (nulovou hypotézu) a použijeme vzorová data k testování, zda je nárok platný. Pokud tvrzení není pravdivé, zvolíme alternativní hypotézu. Vše je velmi jednoduché.
Abychom zjistili, zda je tvrzení platné nebo ne, použijeme p-hodnotu ke zvážení síly důkazu, abychom zjistili, zda je statisticky významný. Pokud důkazy podporují alternativní hypotézu, pak zamítneme nulovou hypotézu a přijmeme alternativní hypotézu. To bude vysvětleno v další části.
Použijme příklad k objasnění tohoto konceptu a tento příklad bude použit v celém tomto článku pro další koncepty.
Příklad. Řekněme, že pizzerie tvrdí, že její doba dodání je v průměru 30 minut nebo méně, ale vy si myslíte, že je to déle. Spustíte tedy test hypotézy a náhodně vyberete dodací lhůtu pro testování nároku:
- Nulová hypotéza – průměrná doba dodání je 30 minut nebo méně
- Alternativní hypotéza — průměrná doba doručení přesahuje 30 minut
- Cílem je zde určit, které tvrzení, nulové nebo alternativní, je lépe podpořeno daty získanými z našich ukázkových dat.
Jedním z běžných způsobů testování hypotéz je použití Z-testu. Nebudeme zde zacházet do přílišných podrobností, protože chceme lépe porozumět tomu, co se děje na povrchu, než se ponoříme hlouběji.
2. Normální rozdělení
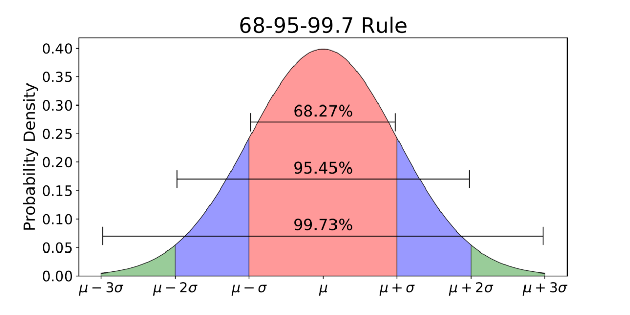
Normální rozdělení je funkce hustoty pravděpodobnosti používaná k zobrazení rozložení dat.
Normální rozdělení má dva parametry, průměr (μ) a směrodatnou odchylku, nazývanou také sigma (σ).
Průměr je centrální tendencí distribuce. Určuje umístění píku pro normální rozdělení. Směrodatná odchylka je mírou variability. Určuje, jak daleko od průměru mají hodnoty tendenci klesat.
Normální rozdělení je běžně spojováno s pravidlem 68-95-99.7 (obrázek výše).
- 68 % dat je v rámci 1 standardní odchylky (σ) od průměru (μ)
- 95 % dat je v rozmezí 2 standardních odchylek (σ) od průměru (μ)
- 99,7 % dat je v rozmezí 3 standardních odchylek (σ) od průměru (μ)
Ochladit. Možná se teď ptáte: “Jak souvisí normální rozdělení s naším předchozím testem hypotéz?”
Protože jsme k testování naší hypotézy použili Z-test, musíme vypočítat Z-skóre (které budeme používat v naší testovací statistice), což je počet standardních odchylek od průměru datového bodu. V našem případě je každý datový bod časem doručení pizzy, který jsme obdrželi.
Všimněte si, že když jsme vypočítali všechna Z-skóre pro každou dobu dodání pizzy a vynesli standardní normální distribuční křivku, jak je uvedeno níže, jednotka na ose X se změní z minut na jednotky standardní odchylky, protože jsme proměnnou standardizovali odečtením průměru a vydělením směrodatnou odchylkou (viz vzorec výše).
Studium standardní křivky normálního rozdělení je užitečné, protože můžeme porovnat výsledky testu s „normální“ populací se standardizovanou jednotkou ve směrodatné odchylce, zvláště když máme proměnnou, která přichází s různými jednotkami.
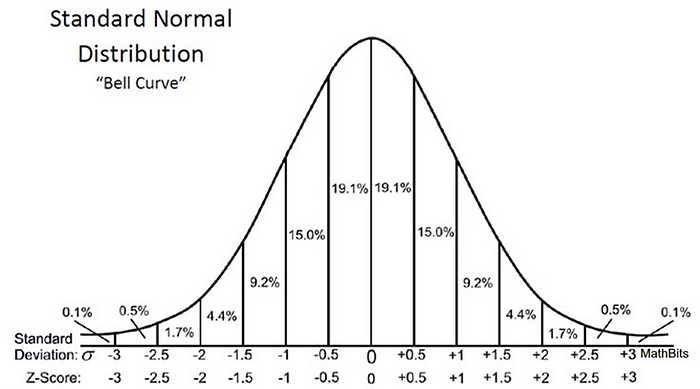
Z-skóre nám může říci, kde leží celková data ve srovnání s průměrem populace.
Líbí se mi, jak to řekl Will Koersen: čím vyšší nebo nižší Z-skóre, tím méně pravděpodobné, že výsledek bude náhodný, a tím pravděpodobnější bude významný.
Ale jak vysoké (nebo nízké) je číslo považováno za dostatečně přesvědčivé, aby bylo možné kvantifikovat, jak významné jsou naše výsledky?
Climax
Zde potřebujeme poslední dílek skládačky – p-hodnotu a zkontrolujeme, zda jsou naše výsledky statisticky významné na základě hladiny významnosti (známé také jako alfa), kterou jsme nastavili před zahájením našeho experimentu.
3. Co je P-hodnota?
Konečně… Tady mluvíme o p-hodnotě!
Všechna předchozí vysvětlení mají připravit půdu a vést nás k této P-hodnotě. Potřebujeme nějaký předchozí kontext a kroky, abychom pochopili tuto záhadnou (ve skutečnosti ne tak záhadnou) p-hodnotu a jak to může vést k našim rozhodnutím o testování hypotéz.
Pokud jste se dostali až sem, pokračujte ve čtení. Protože tato sekce je ze všech nejvíce vzrušující!
Namísto vysvětlování p-hodnot pomocí definice dané Wikipedií (promiň Wikipedie), pojďme to vysvětlit v našem kontextu – dodací lhůty pizzy!
Připomeňme, že jsme náhodně vybrali některé časy rozvozu pizzy a cílem je zkontrolovat, zda doba doručení nepřesahuje 30 minut. Pokud konečné důkazy podporují tvrzení pizzerie (průměrná doba doručení je 30 minut nebo méně), pak bychom nulovou hypotézu nezamítli. V opačném případě nulovou hypotézu zamítneme.
Úkolem p-hodnoty je tedy odpovědět na tuto otázku:
Pokud žiji ve světě, kde doba dodání pizzy je 30 minut nebo méně (nulová hypotéza je pravdivá), jak překvapivé jsou mé skutečné důkazy?
P-hodnota na tuto otázku odpovídá číslem – pravděpodobností.
Čím nižší je p-hodnota, tím neočekávanější jsou důkazy, tím směšnější se naše nulová hypotéza zdá.
A co děláme, když si připadáme směšní s naší nulovou hypotézou? Odmítáme ji a volíme naši alternativní hypotézu.
Pokud je p-hodnota pod danou hladinou významnosti (lidé tomu říkají alfa, já tomu říkám práh směšnosti – neptejte se mě proč, jen je to pro mě jednodušší na pochopení), pak nulovou hypotézu zamítneme.
Nyní chápeme, co znamená p-hodnota. Aplikujme to na náš případ.
P-hodnota ve výpočtu doby dodání pizzy
Nyní, když jsme shromáždili nějaké ukázkové údaje o době doručení, provedli jsme výpočet a zjistili jsme, že průměrná doba doručení je o 10 minut delší s p-hodnotou 0,03.
To znamená, že ve světě, kde je doba doručení pizzy 30 minut nebo méně (nulová hypotéza je pravdivá), existuje 3% šance, že uvidíme průměrnou dobu doručení alespoň o 10 minut delší, kvůli náhodnému šumu.
Čím menší je p-hodnota, tím významnější bude výsledek, protože je méně pravděpodobné, že bude způsoben šumem.
V našem případě většina lidí špatně chápe p-hodnotu:
P-hodnota 0,03 znamená, že existuje 3% (procentuální pravděpodobnost), že výsledek je způsoben náhodou – což není pravda.
Lidé často chtějí definitivní odpověď (včetně mě), a proto jsem se dlouho potýkal s interpretací p-hodnot.
P-hodnota *nedokazuje* nic. Je to prostě způsob, jak využít překvapení jako základ pro inteligentní rozhodnutí.
– Cassie Kozyrkov
Zde je návod, jak můžeme použít p-hodnotu 0,03, která nám pomůže učinit inteligentní rozhodnutí (DŮLEŽITÉ):
- Představte si, že žijeme ve světě, kde je průměrná doba doručení vždy 30 minut nebo méně – protože věříme v pizzerii (naše původní přesvědčení)!
- Po analýze doby dodání odebraných vzorků je p-hodnota o 0,03 nižší než hladina významnosti 0,05 (za předpokladu, že jsme tuto hodnotu nastavili před naším experimentem), a můžeme říci, že výsledek je statisticky významný.
- Protože jsme vždy věřili pizzerii, že dokáže splnit svůj slib doručit pizzu do 30 minut nebo méně, musíme nyní zvážit, zda tato víra dává smysl, protože výsledek nám říká, že pizzerie neplní svůj slib a výsledek je statisticky významný.
- Co bychom tedy měli dělat? Nejprve se pokusíme vymyslet jakýkoli možný způsob, jak učinit naše původní přesvědčení (nulovou hypotézu) pravdivé. Ale protože pizzerie postupně dostává špatné recenze od jiných lidí a často poskytuje špatné výmluvy, které vedly ke zpoždění dodávky, i my sami se cítíme směšní, že se na pizzerii vymlouváme, a proto se rozhodneme zamítnout nulovou hypotézu.
- Dalším chytrým rozhodnutím je nekupovat žádnou další pizzu z tohoto místa.
Podle mého názoru se p-hodnoty používají jako nástroj ke zpochybnění našeho původního přesvědčení (nulové hypotézy), když je výsledek statisticky významný. Ve chvíli, kdy si připadáme směšní se svým vlastním přesvědčením (za předpokladu, že p-hodnota ukazuje, že výsledek je statisticky významný), zahodíme své původní přesvědčení (zamítneme nulovou hypotézu) a učiníme racionální rozhodnutí.
4. Statistická významnost
Nakonec je to poslední krok, kdy dáme vše dohromady a zkontrolujeme, zda je výsledek statisticky významný.
Nestačí mít jen p-hodnotu, potřebujeme nastavit práh (hladinu významnosti – alfa). Alfa by měla být vždy nastavena před experimentem, aby se předešlo zkreslení. Pokud je pozorovaná p-hodnota nižší než alfa, pak docházíme k závěru, že výsledek je statisticky významný.
Obecným pravidlem je nastavit alfa na 0,05 nebo 0,01 (opět hodnota závisí na vaší úloze).
Jak již bylo zmíněno dříve, předpokládejme, že jsme před zahájením experimentu nastavili alfa na 0,05, získaný výsledek je statisticky významný, protože p-hodnota 0,03 je nižší než alfa.
Pro informaci jsou níže uvedeny hlavní fáze celého experimentu:
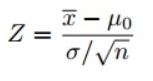
- Formulujte nulovou hypotézu
- Formulujte alternativní hypotézu
- Určete hodnotu alfa, kterou chcete použít
- Najděte Z-skóre spojené s vaší úrovní alfa
- Najděte statistiku testu pomocí tohoto vzorce
- Pokud je hodnota testovací statistiky menší než z-skóre na úrovni alfa (nebo je hodnota p menší než hodnota alfa), zamítněte nulovou hypotézu. V opačném případě nulovou hypotézu nezamítejte.
Pokud se chcete dozvědět více o statistické významnosti, neváhejte se podívat na tento článek – Vysvětlení statistické významnosti od Willa Kersena.
Další myšlenky
Tady je toho hodně k trávení, že?
Nemohu popřít, že p-hodnoty jsou ze své podstaty pro mnoho lidí matoucí, a trvalo mi docela dlouho, než jsem skutečně pochopil a ocenil význam p-hodnot a jak je lze použít jako součást našeho rozhodovacího procesu jako datových vědců.
Na p-hodnoty se ale příliš nespoléhejte, protože pomáhají jen v malé části celkového rozhodovacího procesu.
Doufám, že mé vysvětlení p-hodnot bylo intuitivní a pomohlo vám pochopit, co p-hodnoty ve skutečnosti znamenají a jak je lze použít při testování vašich hypotéz.
Samotný výpočet p-hodnot je jednoduchý. Záludná část nastává, když chceme interpretovat p-hodnoty v testech hypotéz. Doufám, že nyní bude pro vás ta obtížná část o něco jednodušší.
Pokud se chcete o statistice dozvědět více, vřele vám doporučuji přečíst si tuto knihu (kterou právě čtu!) – Praktická statistika pro datové vědce, napsaná speciálně pro datové vědce, aby si osvojili základní pojmy statistiky.

Zjistěte podrobnosti o tom, jak získat vyhledávanou profesi od nuly nebo Level Up, pokud jde o dovednosti a plat, absolvováním placených online kurzů SkillFactory:
- Školení v oboru Data Science od nuly (12 měsíců)
- Profese analytika s jakoukoli počáteční úrovní (9 měsíců)
- Kurz strojového učení (12 týdnů)
- Kurz Python for Web Development (9 měsíců)
- Kurz DevOps (12 měsíců)
- Profese webový vývojář (8 měsíců)
Přečtěte si více
- Trendy v datové vědě 2020
- Data Science je mrtvá. Ať žije obchodní věda
- Skvělí datoví vědci neztrácejí čas se statistikami
- Jak se stát datovým vědcem bez online kurzů
- 450 bezplatných kurzů Ivy League
- Data Science for Humanities: Co jsou to „data“
- Data Science on Steroids: Úvod do rozhodovací inteligence